Cost Results over AI SW stacks
End-to-end Task
Object Detection

동일 H/W 환경에서 세계적으로 유명한 딥러닝 프레임워크와 비교 결과,
실시간 객체 감지 작업에서 훨씬 더 적은 컴퓨팅 리소스로 월등한 성능 구현
- 응답시간3배 감소
- 메모리 사용6배 감소
High-level S/W Stack
Tensor Operations

다른 벤더사 제품들 대비 다양한 텐서 연산 작업들에서
최대 3배 적은 메모리 사용과 10배 계산 속도 향상 검증
- 응답시간10배 감소
- 메모리 사용3배 감소
Middle-level S/W Stack
Deep Learning Primitives

Metep의 혁신적인 자체 Convolution 연산 알고리즘을 통해
다양한 자체 딥러닝 연산 알고리즘 지원
- 응답시간5배 감소
- 메모리 사용3배 감소
Low-level S/W Stack
BLAS & Compute-Kernels

Metep의 독자적인 기술인 자체 GEMM 계산 커널 알고리즘을 통해
모든 레벨이 C++ 환경에서 연동 가능
- 응답시간2.5배 감소
- 메모리 사용1.6배 감소
High-level Tensor Operations
Comparative benchmarks for Metep’s tensor operations to other vendors
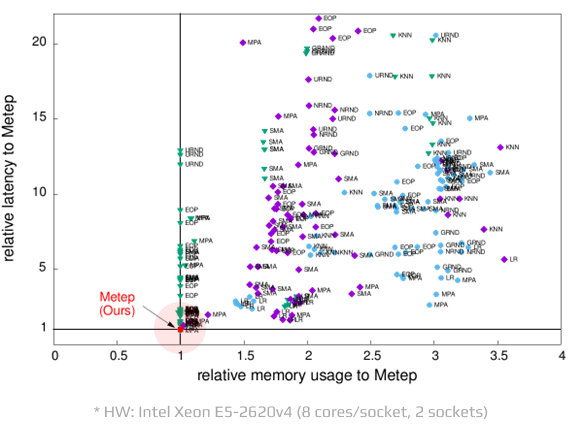
Metep은 다른 벤더의 제품들 대비
다양한 텐서 연산 작업들에서
최대 3배 적은 메모리 사용과 10배의 계산 속도 향상을
가능하게 합니다.
Middle-level Primitives
Comparative benchmarks for Metep’s convolution operator to other vendors
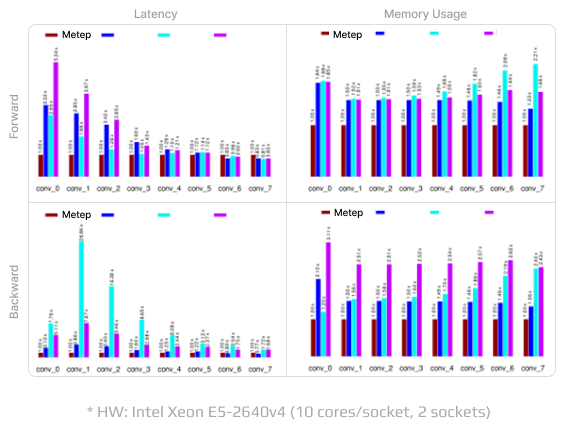
Metep의 혁신적인 자체 Convolution 연산 알고리즘은
다른 벤더의 최적화된 소프트웨어 알고리즘 대비
최대 3x 적은 메모리 사용과 5x의 계산 속도 향상을
가능하게 하여 CNN 모델을 혁신하고 있습니다.
Low-level Compute-Kernels
Comparative benchmarks for Metep’s tensor operations to other vendors
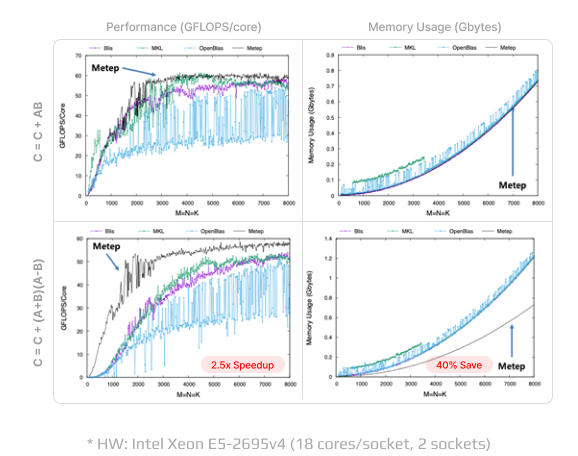
Metep의 자체 GEMM 계산 커널 알고리즘은
다른 벤더의 최적화된 GEMM 커널과 비교하여
fused matrix multiplication 작업에서
최대 40% 적은 메모리 사용과 2.5x 계산 속도 향상을 제공합니다.



