Cost Results over AI SW stacks
End-to-end Task
Object Detection

Compared to globally renowned deep learning frameworks on the same hardware, Metep delivers superior performance in real-time object detection tasks with significantly fewer computing resources
- 3x faster response times
- 6x reduction in memory usage
High-level S/W Stack
Tensor Operations

In various tensor operations, Metep demonstrates up to 3x lower memory usage and a 10x increase in computational speed compared to other vendors' products
- 10x faster response times
- 3x reduction in memory usage
Middle-level S/W Stack
Deep Learning Primitives

Metep supports a wide range of proprietary deep learning operation algorithms through its innovative, in-house convolution operation algorithm
- 5x faster response times
- 3x reduction in memory usage
Low-level S/W Stack
BLAS & Compute-Kernels

With Metep's unique GEMM computation kernel algorithm, all levels integrate seamlessly in a C++ environment
- 2.5x faster response times
- 1.6x reduction in memory usage
High-level Tensor Operations
Comparative benchmarks for Metep’s tensor operations to other vendors
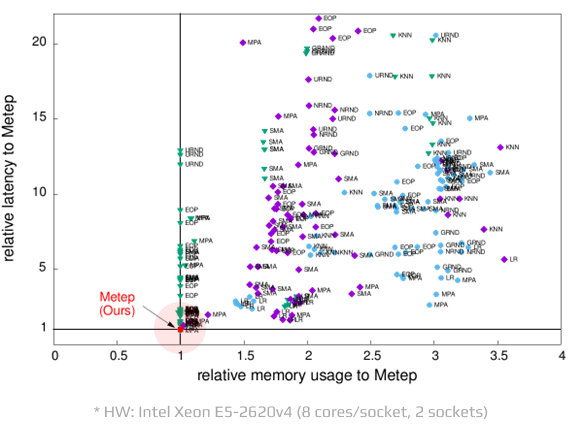
Metep enables up to 3x lower memory usage and a 10x boost in computational speed across various tensor operations, outperforming products from other vendors
Middle-level Primitives
Comparative benchmarks for Metep’s convolution operator to other vendors
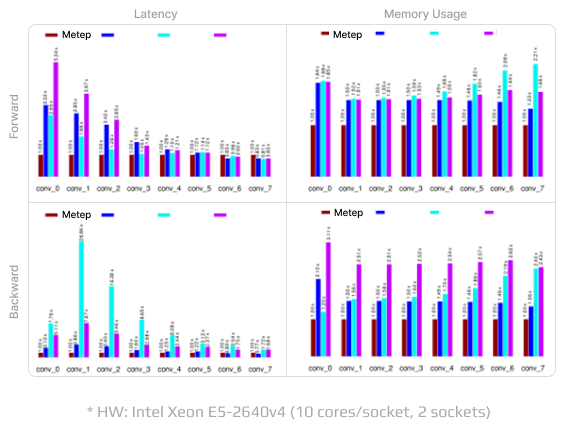
Metep's innovative convolution operation algorithm brings groundbreaking advancements to CNN models, achieving up to 3x lower memory usage and 5x faster computation compared to other vendors' optimized software algorithms
Low-level Compute-Kernels
Comparative benchmarks for Metep’s tensor operations to other vendors
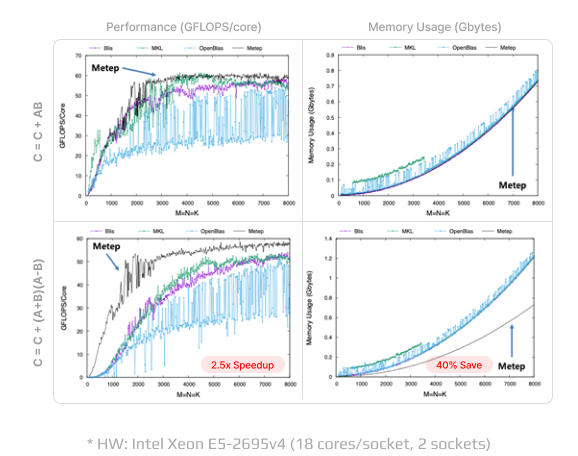
Metep’s proprietary GEMM computation kernel algorithm provides up to 40% lower memory usage and a 2.5x increase in computational speed for fused matrix multiplication tasks compared to other optimized GEMM kernels



